
1
Overview
Konica Minolta provides industry-specific translation services called MELON and KOTOBAL. These services operate on tablet devices and offer multilingual machine interpretation through speech recognition and machine translation, combined with a hybrid interpreting function supported by operators. Speech recognition accuracy is critical to service quality. In particular, because these are industry-specific services, accurate recognition of technical terms and Japanese language expressions is an important requirement. In this study, to improve the accuracy of an industry-specific speech recognition engine, we collected technical terms used in the target industries and built training data using synthesized speech. This approach enabled the construction of a specialized model while reducing data creation costs. We also built an MLOps system with productization cycles in mind. As a result, we can accelerate the training cycle of the speech recognition engine, improve product performance, and ultimately deliver greater customer value (Fig. 1).
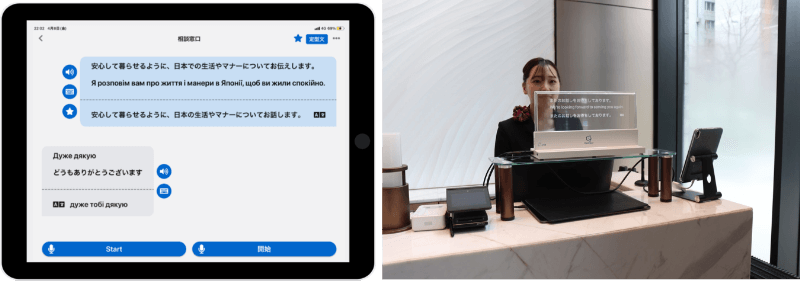
Fig. 1 Example of service usage with a transparent display
2
Details
■Configuration
To train and develop an industry-specific speech recognition engine, the workflow comprises data collection, training, evaluation, and deployment. For speech recognition engines , paired audio and text data must be created, in which the audio corresponds to an utterance of the sentence to be recognized. After collecting the required amount of data, the speech recognition engine is trained, evaluated (e.g., by comparing performance with an existing engine), and then integrated into the service (deployed).
■Functions / Features / Applications
1. Building training data, including technical terms
To create an industry-specific engine, collecting technical terms for the target industry and building corresponding speech data are necessary. While collecting technical terms is relatively straightforward, collecting speech data that includes these terms typically requires human read-aloud, resulting in substantial labor costs. In addition, MELON and KOTOBAL target the medical, tourism, and municipal government domains, in which new terms are introduced daily because of domain specificity and emerging trends. When human read-aloud is used as the primary method, it is difficult to conduct fine-grained and rapid improvement cycles.
Therefore, after collecting technical terms, we built the speech dataset using a large language model and synthesized speech (Fig. 2). This approach eliminates labor costs associated with building datasets for technical terms and enables faster training cycles for newly introduced terms.
Table 1 presents the training and evaluation results of the new speech recognition engine. In this study, training was performed not only with the dataset containing technical terms but also with an additional general Japanese speech dataset. We evaluated Japanese recognition accuracy using the word error rate (WER) and character error rate (CER), as well as technical term recognition accuracy. The results confirm improvements in both Japanese recognition accuracy and technical term recognition accuracy compared with the existing engine deployed in the service.
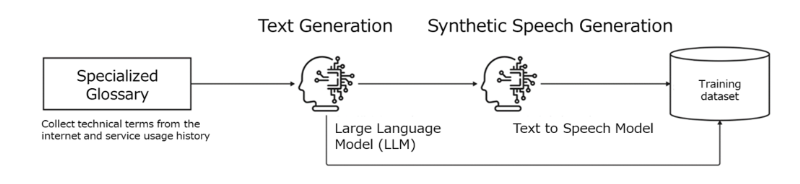
Fig. 2 Workflow for building training data including technical terms
Table 1 Training results using the technical term dataset

2. Improving the training cycle
To improve the training cycle, we used QuickAnno1), which was developed by Konica Minolta. This system provides automatic labeling using a dedicated AI model and includes a retraining function that utilizes data within the tool. By integrating with annotation tools such as LabelStudio and with MLflow, a tool for managing training results, it contributes to improved efficiency in AI development. We registered the training data, including the technical terms described in Section 1, in LabelStudio and built an environment in which training and evaluation of the speech recognition engine can be completed entirely through the user interface.
■Future outlook
At present, development of the speech recognition engine is limited to Japanese; however, products require improved recognition accuracy in multiple languages. We will therefore enhance performance in languages other than Japanese in future product cycles.

