
ニュース
2025年7月18日 出展
画像の認識・理解シンポジウム「MIRU2025」に5件の論文を発表 ~口頭発表1件採択、シルバースポンサーとしても協賛~
コニカミノルタ株式会社(以下 コニカミノルタ)は、画像認識および言語処理AI技術に関する論文5件を、画像認識分野の国内の主要会議「MIRU2025」にて発表いたします。
MIRUは、大学・企業を問わず、基礎から応用に至る最新研究が活発に議論される国内最大規模の画像系認識分野のシンポジウムです。
今回、当社からは計5件の研究発表を予定しており、内1件は採択率約30%の口頭発表のプログラムに選ばれました。
また、コニカミノルタはMIRU2025のシルバースポンサーとして本シンポジウムを協賛いたします。当日は企業ブースも出展し当社のAI技術への取り組みをご紹介いたします。論文の発表と合わせて、ぜひブースにもお立ち寄りください。
コニカミノルタは、独自のイメージング技術と最新のAI技術を掛け合わせ、”見たことのない”価値を創造していきます。
【口頭発表論文】
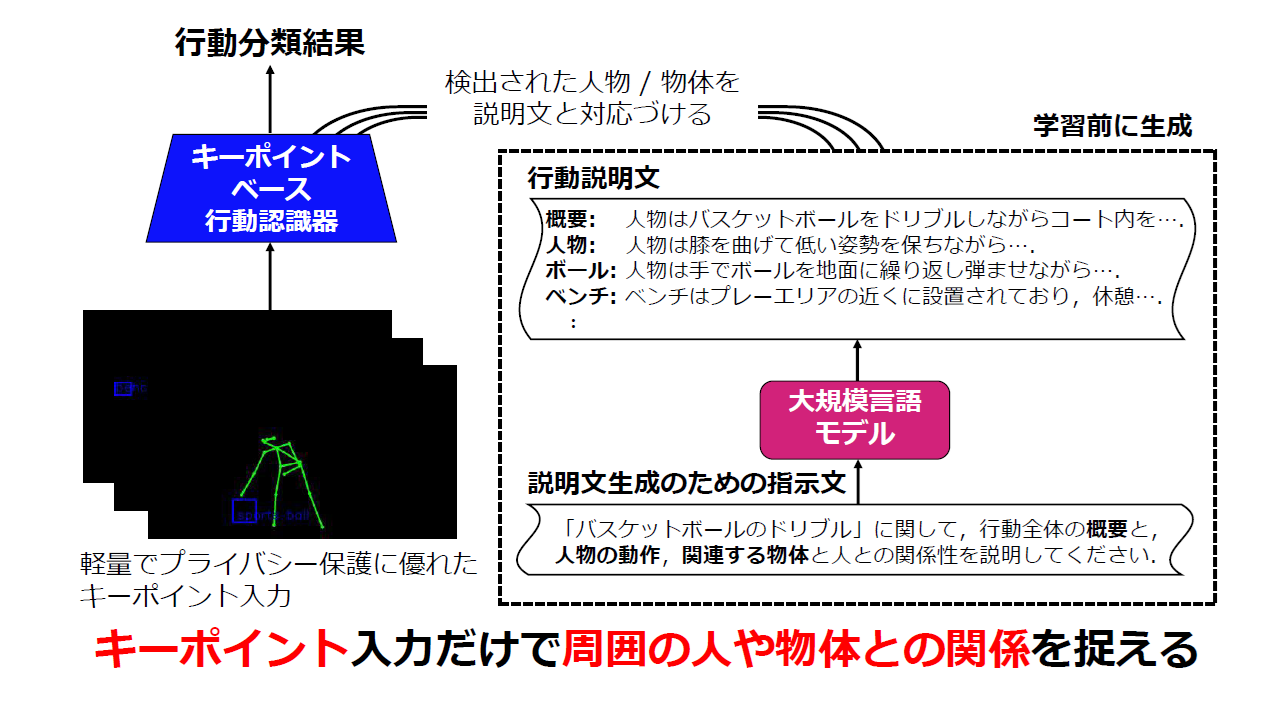
● OS1C-04「InsAT: 周囲の物体や他者との関係を考慮するキーポイントベース行動認識」
著者:
筒川 和樹、長野 紘士朗、佐藤 文彬(コニカミノルタ)
紹介:
人物と物体の時系列キーポイントに対し、自然言語によるインスタンス記述を教師信号として用いる行動認識フレームワークを提案しました。学習効率を高め、データ効率の高い認識システムへの応用が期待されます。
【デモ発表論文】
● DS-04「KIND: インスタンス単位の知識転移を用いたキーポイントベースゼロショット行動認識」
著者:
筒川 和樹、長野 紘士朗、佐藤 文彬(コニカミノルタ)
紹介:
人物と物体の時系列キーポイントと、ユーザが自由に入力した自然言語記述を照合し、行動を検出する技術を開発しました。製造現場など設置環境ごとに異なる行動定義にも柔軟に対応できる可能性があります。
【ポスター発表論文】
● IS1-051「特徴空間における位置情報を条件付けに用いた拡散モデルの生成制御手法」
著者:早田 啓介(コニカミノルタ)
紹介:
画像生成AIで、どんな特徴の画像を作るかを詳細に指定できる手法の提案です。
クラス識別モデルの学習データ拡張時に、判別が難しい境界線上のデータを狙って生成することで、モデル学習の効率を大幅に向上させる応用が期待できます。
● IS2-141「視覚言語モデルを用いたGitHubスクリーンショットによる日本語言語資源自動識別と研究分野マルチラベル分類」
著者:
池田 大志、Quan HoangDanh、長野 紘士朗、早田 啓介(コニカミノルタ)
紹介:
日本語の言語資源の検索性向上を目的として、研究では視覚言語モデルを活用し、GitHubリポジトリのスクリーンショット画像を入力とする言語資源の自動識別および研究分野のマルチラベル分類手法を提案します。
● IS3-072「事前学習済みDNNを更新しない一般化Few-Shot物体検出」
著者:
長野 紘士朗(コニカミノルタ、慶應義塾大学)、佐藤 文彬(コニカミノルタ)、八馬 遼(NVIDIA)、筒川 和樹(コニカミノルタ)、関井 大気(サイバーエージェント)
紹介:
大規模な画像・テキストで事前学習した Vision-Language 基盤モデルを活用し、モデルの重み・構造を変えずに、新たな物体の外観特徴を検出する手法を提案。本手法に関する論文は、国際会議ICIPにも投稿し採択されました。